- Омниканальный HelpDeskРаботайте с более чем 50 каналами. Определяйте, приоритезируйте, планируйте и масштабируйте поддержку при помощи искусственного интеллекта.
- Мониторинг социальних сетейОтслеживайте разговоры в социальных сетях. Понимайте настроения, желания и намерения.
- Аналитика рекламыОтслеживайте и анализируйте рекламу ваших дистрибьюторов и конкурентов.
- Мониторинг отзывовПолучайте комплексное освещение и понимание отзывов о продуктах и локациях.
- Мониторинг новостейПолучайте доступ к новостям в реальном времени из более 100 тыс. источников в более чем 130 странах мира.
- Мониторинг цены и рекламыКонтролируйте цены и наличие товаров на тысячах сайтов электронной коммерции.
- Omnichannel BIВыявляйте тенденции, закономерности и аномалии. Делайте стратегические прогнозы с помощью искусственного интеллекта.
- Мониторинг мессенджеровПолучайте ценную информацию из каналов обмена сообщениями, с соблюдением всех требований законодательства.
- Защита от цифровых угроз (DRP)Выявляйте вредоносные домены, боты и дезинформацию. Защитите цифровые активы от подделок.























SemanticForce
SemanticForce - это многоканальная платформа мониторинга, аналитики медиа и обслуживания клиентов, основанная на передовом семантическом и визуальном анализе.
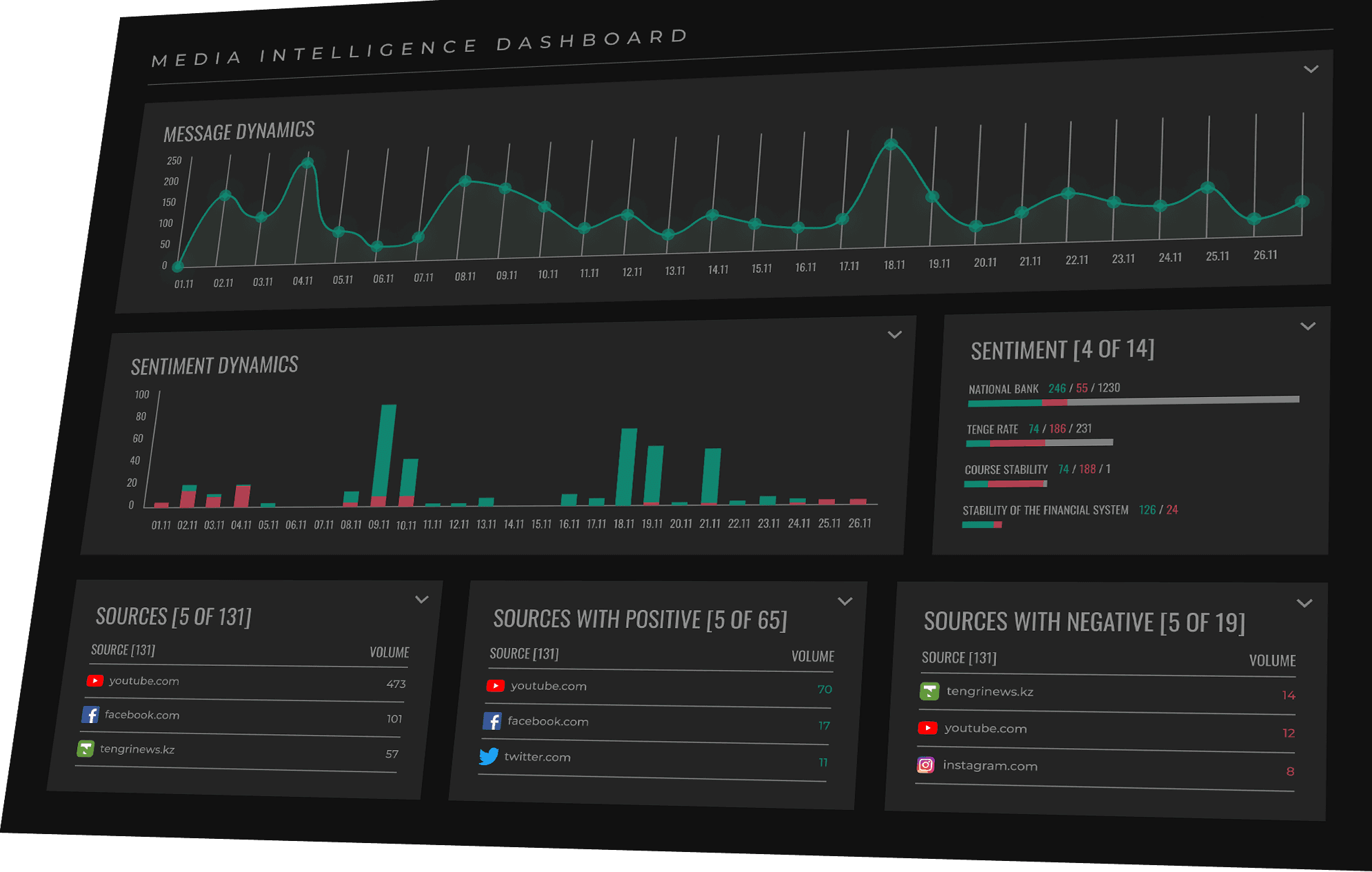























ТИПЫ ДАННЫХ И ИСТОЧНИКИ
Традиционные платформы анализа СМИ предоставляют ограниченные типы данных. Платформа средств массовой информации SemanticForce, обеспечивающая полный цикл разведки, предоставляет вам видимость и интеллектуальные данные повсюду. От новостей в Интернете до форумов, от влиятельных личностей до доменов, от рекламы до ценообразования наша экосистема обеспечивает новый уровень интеллекта и защиты.
ОДНА ЭКОСИСТЕМА — МНОЖЕСТВО ВАРИАНТОВ ИСПОЛЬЗОВАНИЯ.


Интеллектуальная и гибкая платформа создания отчетов. Использует компоненты визуализации собственной разработки и встроенный уровень инсайтов.

Анализируйте миллионы сообщений на новостных сайтах и в социальных сетях, чтобы быть в курсе трендов и использовать темы, которые волнуют аудиторию

Расширенная классификация.Тональность на уровне бренда и аспекта. Анализ визуальных данных: распознавание логотипов, объектов и обстановки.

Выявляйте сообщения, которые требуют немедленной реакции. Где бы они ни находились — в социальных сетях, мессенджерах, на сайтах отзывов или форумах — вы сможете ответить на них из одного-единственного окна.

Получайте данные о ценах и наличии в тысячах интернет-магазинов. Следите за рекламой своих дистрибьюторов, торговых посредников и конкурентов.

Выявляйте злонамеренные группы. Определяйте ботов, троллей и охватдезинформации. Защититесь от мошенников, выдающих себя за представителей вашей компании, и прочих угроз в социальных сетях.

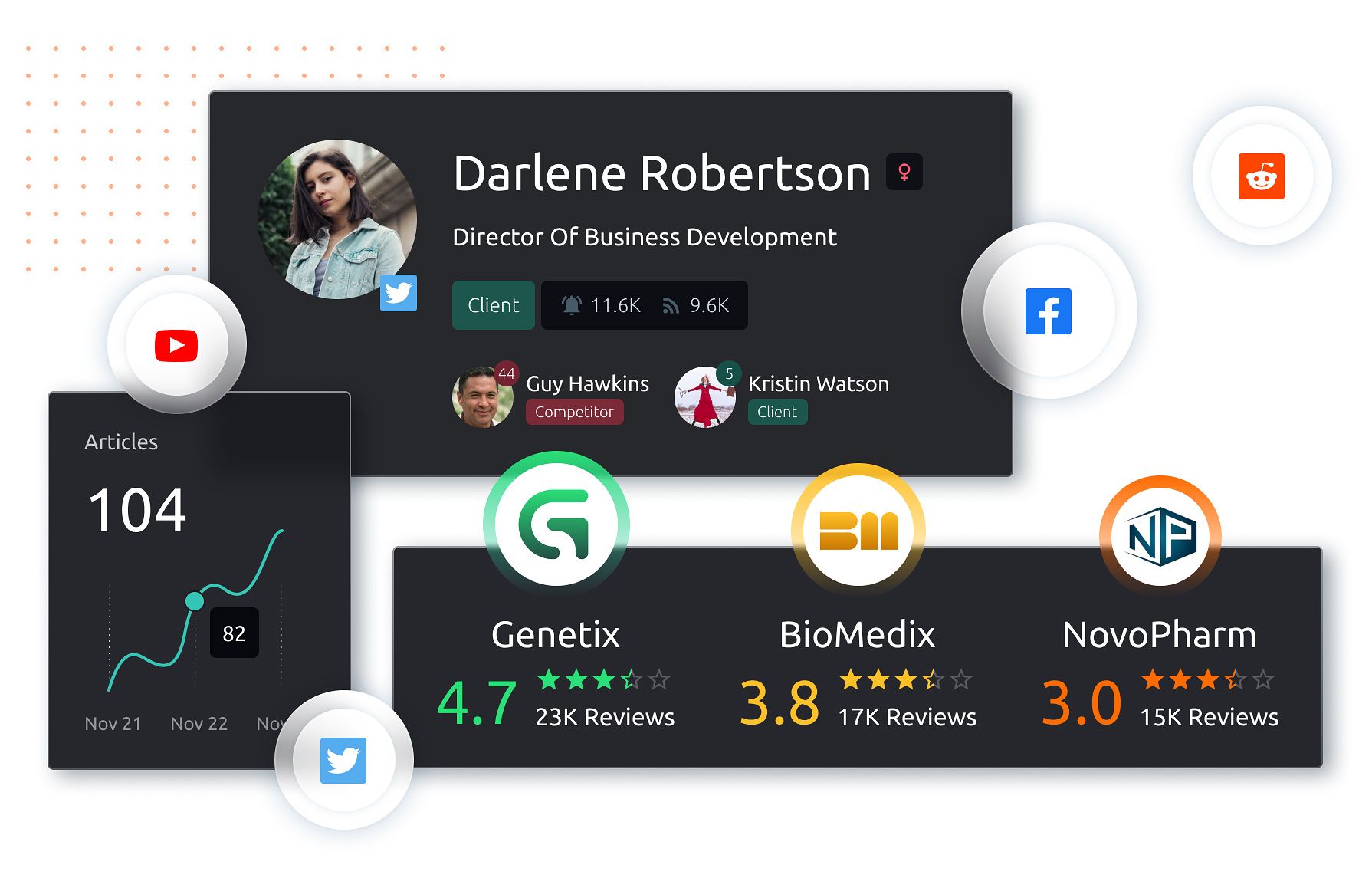
Расширенный анализ аудитории при помощи технологии ProfileForce. Определяйте интересы, следите за поведением, находите сценарии.
Интеллектуальная и гибкая платформа создания отчетов. Использует компоненты визуализации собственной разработки и встроенный уровень инсайтов.
Анализируйте миллионы сообщений на новостных сайтах и в социальных сетях, чтобы быть в курсе трендов и использовать темы, которые волнуют аудиторию

Мониторинг Новостей и Социальных Сетей
Анализ Текстовых и Визуальных Данных
Omnichannel Helpdesk
Анализ Цен и Рекламы
Защита от Дезинформации и Угроз
Аудитория
SemanticForce BI
КАК SEMANTICFORCE МОЖЕТ ПОМОЧЬ ВАШЕМУ БИЗНЕСУ
- Управляйте репутацией вашего бренда
Отслеживайте восприятие клиентами вашего бренда на различных платформах, и должным образом реагируйте на их отзывы.
Получить бесплатно - Проводите быстрые маркетинговые исследования
Получайте информацию о настроениях клиентов относительно вашего бизнеса, бренда, продуктов и конкурентов в режиме реального времени.
Получить бесплатно - Масштабируйте омниканальную поддержку
Общайтесь с клиентами во всех цифровых каналах в режиме единого окна при помощи искусственного интеллекта (AI).
Получить бесплатно - Измеряйте маркетинговую эффективность
Анализируйте ключевые показатели, такие как охват, вовлеченность, настроения, share of voice и другие в онлайн-медиа.
Получить бесплатно - Находите инфлюенсеров и амбассадоров бренда
Узнавайте перечень и информацию о тех, кто имеет большую и лояльную аудиторию в социальных сетях и может эффективно продвигать ваш бренд.
Получить бесплатно


Управляйте репутацией вашего бренда
Отслеживайте восприятие клиентами вашего бренда на различных платформах, и должным образом реагируйте на их отзывы.
Проводите быстрые маркетинговые исследования
Получайте информацию о настроениях клиентов относительно вашего бизнеса, бренда, продуктов и конкурентов в режиме реального времени.
Масштабируйте омниканальную поддержку
Общайтесь с клиентами во всех цифровых каналах в режиме единого окна при помощи искусственного интеллекта (AI).
Измеряйте маркетинговую эффективность
Анализируйте ключевые показатели, такие как охват, вовлеченность, настроения, share of voice и другие в онлайн-медиа.
Находите инфлюенсеров и амбассадоров бренда
Узнавайте перечень и информацию о тех, кто имеет большую и лояльную аудиторию в социальных сетях и может эффективно продвигать ваш бренд.
ГЛУБОКИЙ СЕМАНТИЧЕСКИЙ АНАЛИЗ — ОТ ДАННЫХ К ЦЕННОСТИ
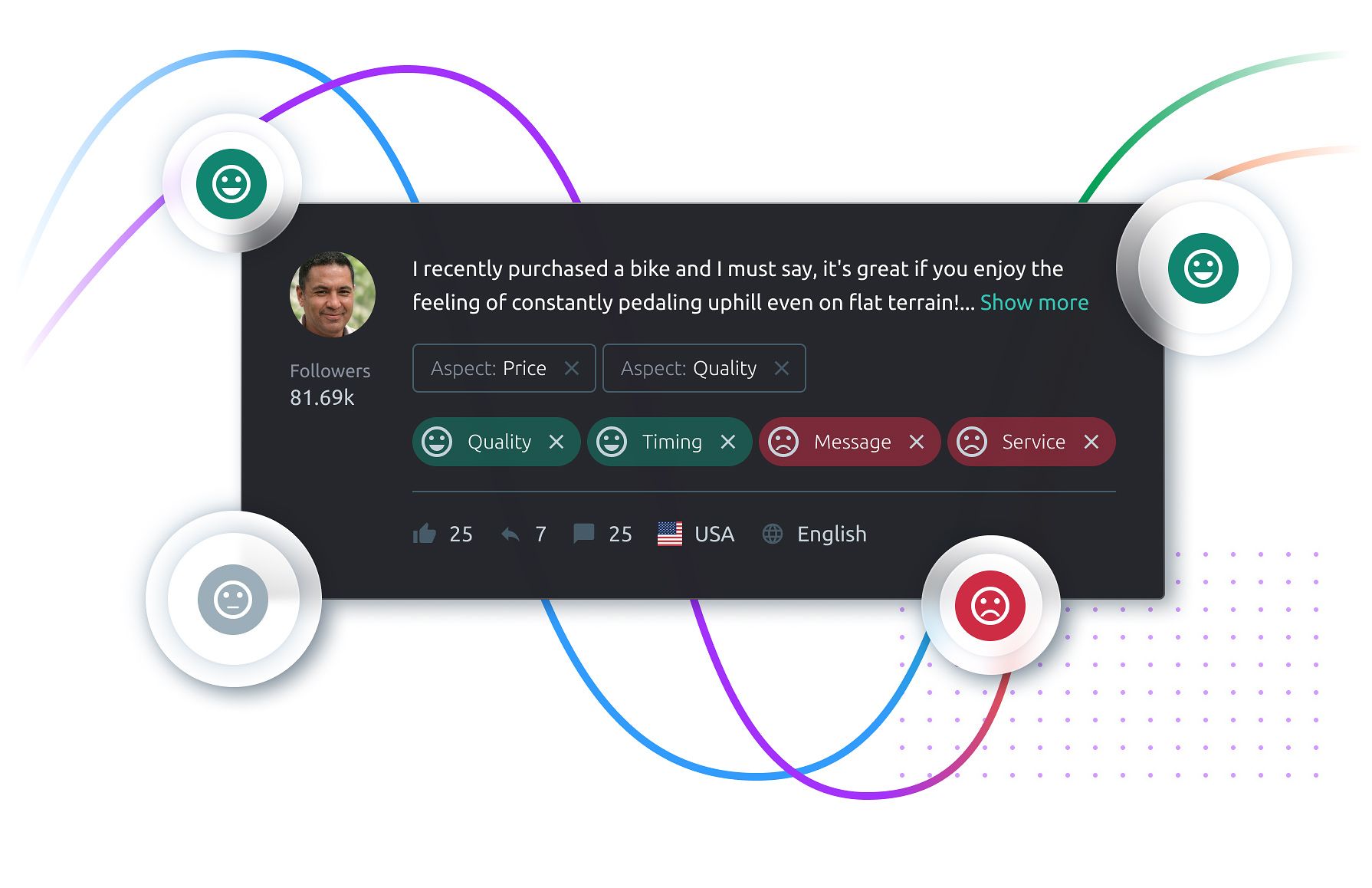
SemanticForce проводит глубокий морфологический, семантический и онтологический анализ текста, чтобы раскрыть его смысл. Платформа понимает сущности, отношения, контекст, тональность и факты. Категоризация, адаптированная для каждого отдельного сайта, превращает неструктурированные данные в инсайты о рынке и позволяет организациям выявлять новые тенденции, находить новые рыночные возможности, проводить сравнение показателей компании и ее конкурентов, защищать ваш бренд от угроз.
SEMANTICFORCE: СЛУШАЙ. ПОНИМАЙ. ДЕЙСТВУЙ.


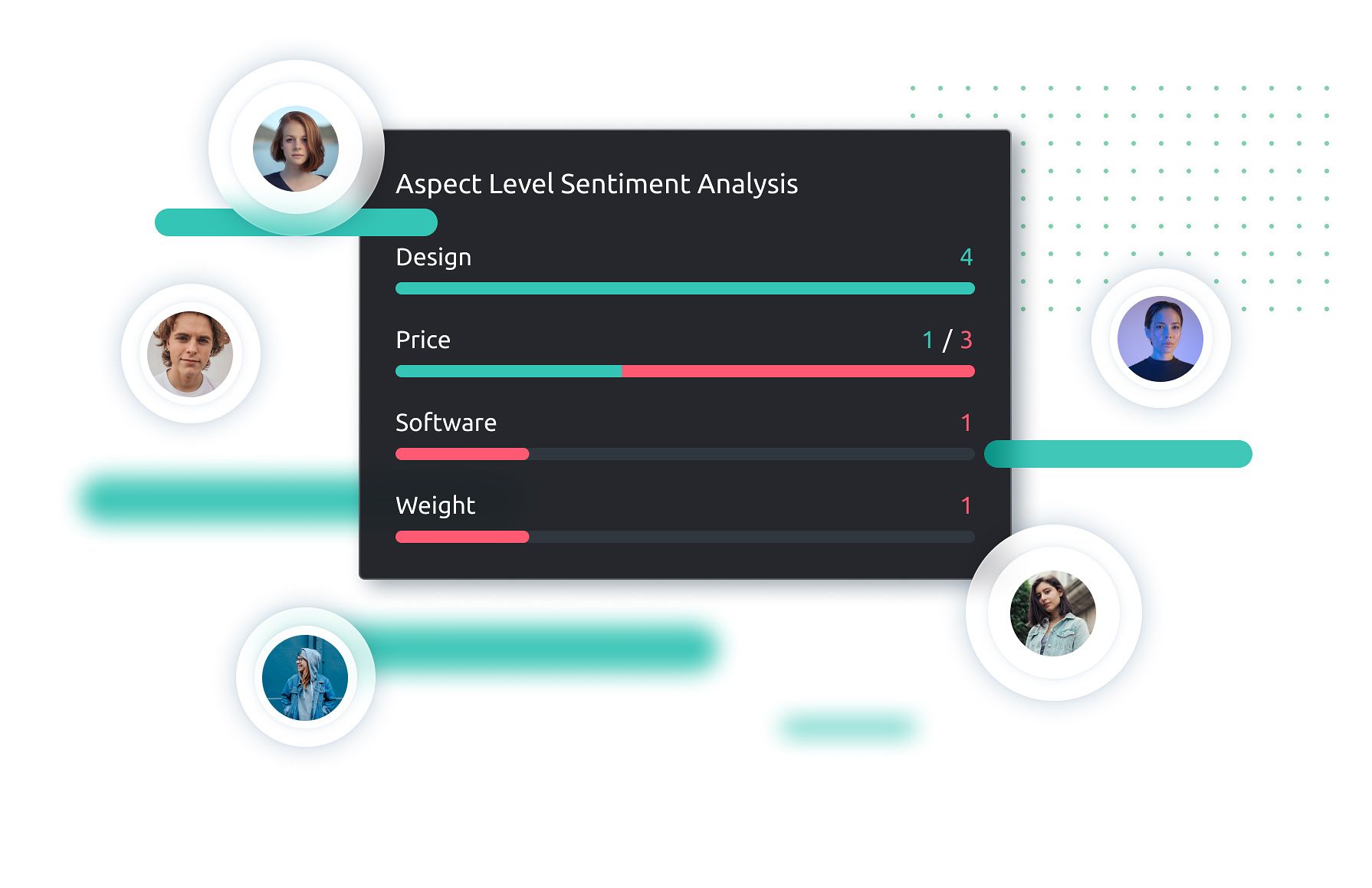
Анализ тональности на уровне аспектов
SemanticForce проводит глубокий морфологический, семантический и онтологический анализ текста, чтобы раскрыть его смысл.
Заявки в службу поддержки
Omnichannel Helpdesk помогает вашей команде эффективно сотрудничать, решая проблемы клиентов.
Категории, товары, артикулы
Оставайтесь в курсе обсуждений благодаря автоматическому определению компаний, людей, брендов, товаров и артикулов.
Риски и угрозы
Защитите свой бренд от угроз и убедитесь, что понимаете стоящие перед ним риски.
Предложения по улучшению
Автоматически находите в сети вопросы, предложения и проблемы пользователей вашей продукции.
ГЛУБОКИЙ АНАЛИЗ ВИЗУАЛЬНОЙ ИНФОРМАЦИИ
Технология искусственного интеллекта SemanticForce Visual-AI позволяет определять логотипы, объекты, текст и место действия на изображениях и видеозаписях. Отслеживайте визуальные упоминания, анализируйте эффективность спонсорства, выявляйте неприемлемое использование элементов вашего бренда при помощи самых современных средств визуальной аналитики SemanticForce. Применяйте этот анализ к самым разным пулам данных — к новостным сайтам, социальным сетям, видеохостингам, сайтам, относящимся к определенной сфере деятельности, рекламе.
Обнаружение логотипа
Обнаружение логотипа — один из наиболее ценных и востребованных визуальных сигналов. Он открывает путь к новым возможностям в анализе данных из социальных сетей.
Распознавание текста
Позволяет идентифицировать и преобразовывать наложенные на изображение символы в машиночитаемый текст. Находите все упоминания бренда, будь то естественные или спонсорские, не будучи обязанными полагаться на хештеги.
Распознавание объектов
Идеально сочетается с модулем обнаружения логотипа, позволяя проще извлекать информацию, которая имеет значение для вашего бренда.
Определение сцен
Технология извлекает сигналы, которые открывает невиданные ранее уровни классификации, позволяя получать беспрецедентную аналитику.
Поиск похожего
Укажите входное изображение и получите возможность найти идентичные или похожие изображения и даже обнаружить товары на основе схожих особенностей дизайна.
ОТЗЫВЫ




Начальник отдела PR
Во-первых, мы искали решение, которое позволило бы нам мониторить весь Интернет в одной системе. Нас интересовало всё: форумы, блоги, онлайн-медиаи т. д. Мы выбрали платформу мониторинга SemanticForce из трех или четырех вариантов, поскольку у всех ее конкурентов нам кое-чего не хватало.
Начальник отдела PR

Менеджер онлайн-поддержки
У нас с самого начала было довольно много требований к системе и возможности ее конфигурирования. Нам нужно было мониторить не только социальные сети, форумы и различные средства массовой информации, но и подключить множество сайтов и интернет-магазинов, на которых мы осуществляли поддержку клиентов и вручную отслеживали отзывы и комментарии покупателей. Казалось, что объединить это всё в одном месте сложно, если не невозможно. Но после достаточно быстрой установки и тестирования мы получили превосходные результаты.
Менеджер онлайн-поддержки


SMM-менеджер
Перед тем, как начать работать с SemanticForce, я провел тщательный сравнительный анализ компаний, занимающихся аналитикой отзывов и упоминаний в социальных сетях. Компания SemanticForce оказалась лидером по количеству и качеству собираемых данных, а также удобству пользования. При этом меня приятно удивила поддержка от сотрудников SemanticForce — они быстро помогли установить систему и ответили на все возникшие вопросы. Признаться, я не ожидал такой оперативности.
SMM-менеджер
Начальник отдела PR
Во-первых, мы искали решение, которое позволило бы нам мониторить весь Интернет в одной системе. Нас интересовало всё: форумы, блоги, онлайн-медиаи т. д. Мы выбрали платформу мониторинга SemanticForce из трех или четырех вариантов, поскольку у всех ее конкурентов нам кое-чего не хватало.
Начальник отдела PR
Менеджер онлайн-поддержки
У нас с самого начала было довольно много требований к системе и возможности ее конфигурирования. Нам нужно было мониторить не только социальные сети, форумы и различные средства массовой информации, но и подключить множество сайтов и интернет-магазинов, на которых мы осуществляли поддержку клиентов и вручную отслеживали отзывы и комментарии покупателей. Казалось, что объединить это всё в одном месте сложно, если не невозможно. Но после достаточно быстрой установки и тестирования мы получили превосходные результаты.
Менеджер онлайн-поддержки
ПОПРОБУЙТЕ SEMANTICFORCE В ДЕЙСТВИИ
Закажите демо-версию в реальном времени, чтобы узнать больше о том, как мониторинг медиаи и электронной коммерции SemanticForce может принести пользу и успех вашему бизнесу.
НАШИ СПЕЦИАЛИСТЫ: